前言:js如何实现一个深拷贝
这是一个老生常谈的问题,也是在求职过程中的高频面试题,考察的知识点十分丰富,本文将对浅拷贝和深拷贝的区别、实现等做一个由浅入深的梳理
# 赋值、浅拷贝与深拷贝的区别
在js中,变量类型分为基本类型和引用类型。对变量直接进行赋值拷贝:
- 对于基本类型,拷贝的是存储在栈中的值
- 对于引用类型,拷贝的是存储在栈中的指针,指向堆中该引用类型数据的真实地址
直接拷贝引用类型变量,只是复制了变量的指针地址,二者指向的是同一个引用类型数据,对其中一个执行操作都会引起另一个的改变。
关于浅拷贝和深拷贝:
- 浅拷贝是对于原数据的精确拷贝,如果子数据为基本类型,则拷贝值;如果为引用类型,则拷贝地址,二者共享内存空间,对其中一个修改也会影响另一个
- 深拷贝则是开辟新的内存空间,对原数据的完全复制
因此,浅拷贝与深拷贝根本上的区别是 是否共享内存空间 。简单来讲,深拷贝就是对原数据递归进行浅拷贝。
三者的简单比较如下:
| 是否指向原数据 | 子数据为基本类型 | 子数据包含引用类型 | |
|---|---|---|---|
| 赋值 | 是 | 改变时原数据改变 | 改变时原数据改变 |
| 浅拷贝 | 否 | 改变时原数据 不改变 | 改变时原数据改变 |
| 深拷贝 | 否 | 改变时原数据 不改变 | 改变时原数据 不改变 |
# 原生浅拷贝方法
数组和对象中常见的浅拷贝方法有以下几种:
- Array.prototype.slice
- Array.prototype.concat
- Array.from
- Object.assign
- ES6解构
使用下面的 用例 1.test.js (opens new window) 进行测试:
const arr = ['test', { foo: 'test' }]
const obj = {
str: 'test',
obj: {
foo: 'test'
}
}
const arr1 = arr.slice()
const arr2 = arr.concat()
const arr3 = Array.from(arr)
const arr4 = [...arr]
const obj1 = Object.assign({}, obj)
const obj2 = {...obj}
//修改arr
arr[0] = 'test1'
arr[1].foo = 'test1'
// 修改obj
obj.str = 'test1'
obj.obj.foo = 'test1'
结果如下:
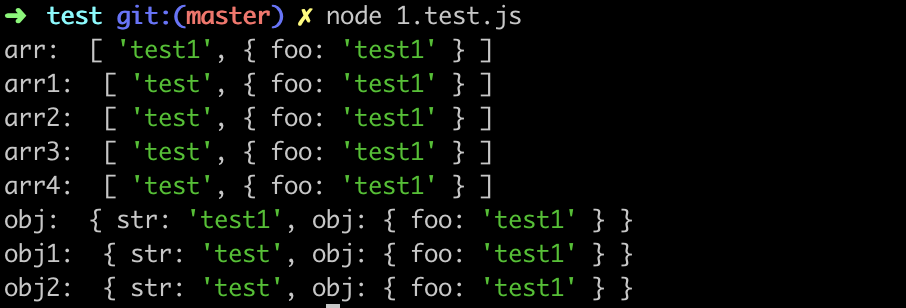
可以看到经过浅拷贝以后,我们去修改原对象或数组中的基本类型数据,拷贝后的相应数据未发生改变;而修改原对象或数组中的引用类型数据,拷贝后的数据会发生相应变化,它们共享同一内存空间
# 深拷贝实现
这里我们列举常见的深拷贝方法并尝试自己手动实现,最后对它们做一个总结、比较
# 1. JSON序列化快速实现
使用 JSON.parse(JSON.stringify(data)) 来实现深拷贝,这种方法基本可以涵盖90%的使用场景,但它也有其不足之处,涉及到下面这几种情况下时则需要考虑使用其他方法来实现深拷贝:
JSON.parse只能序列化能够被处理为JSON格式的数据,因此无法处理以下数据- 特殊数据例如
undefined、NaN、Infinity等 - 特殊对象如时间对象、正则表达式、函数、Set、Map等
- 对于循环引用(例如环)等无法处理,会直接报错
- 特殊数据例如
JSON.parse只能序列化对象可枚举的自身属性,因此会丢弃构造函数的constructor
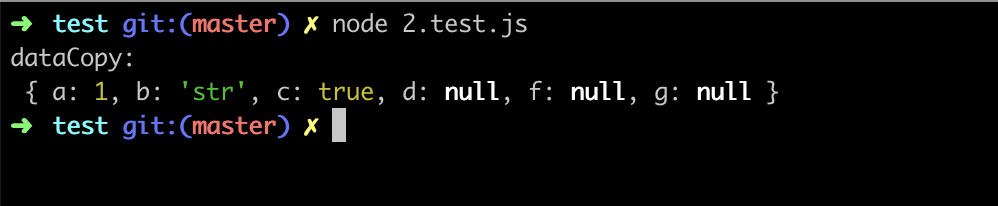
使用下面的 用例 2.test.js (opens new window) 来对基本类型进行验证:
const data = {
a: 1,
b: 'str',
c: true,
d: null,
e: undefined,
f: NaN,
g: Infinity,
}
const dataCopy = JSON.parse(JSON.stringify(data))
可以看到 NaN 、 Infinity 在序列化的过程中被转化为了 null ,而 undefined 则丢失了:
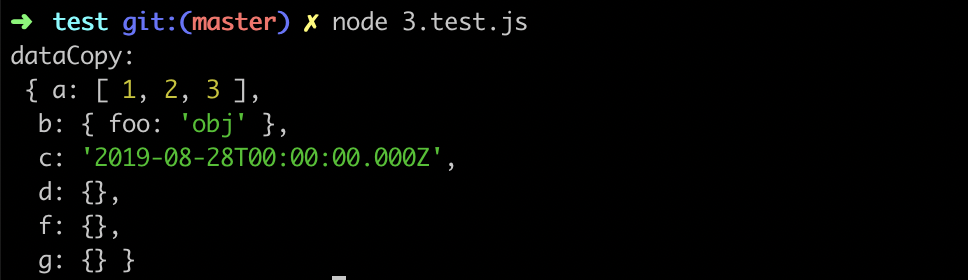
再使用 用例 3.test.js (opens new window) 对引用类型进行测试:
const data = {
a: [1, 2, 3],
b: {foo: 'obj'},
c: new Date('2019-08-28'),
d: /^abc$/g,
e: function() {},
f: new Set([1, 2, 3]),
g: new Map([['foo', 'map']]),
}
const dataCopy = JSON.parse(JSON.stringify(data))
对于引用类型数据,在序列化与反序列化过程中,只有数组和对象被正常拷贝,其中时间对象被转化为了字符串,函数会丢失,其他的都被转化为了空对象:
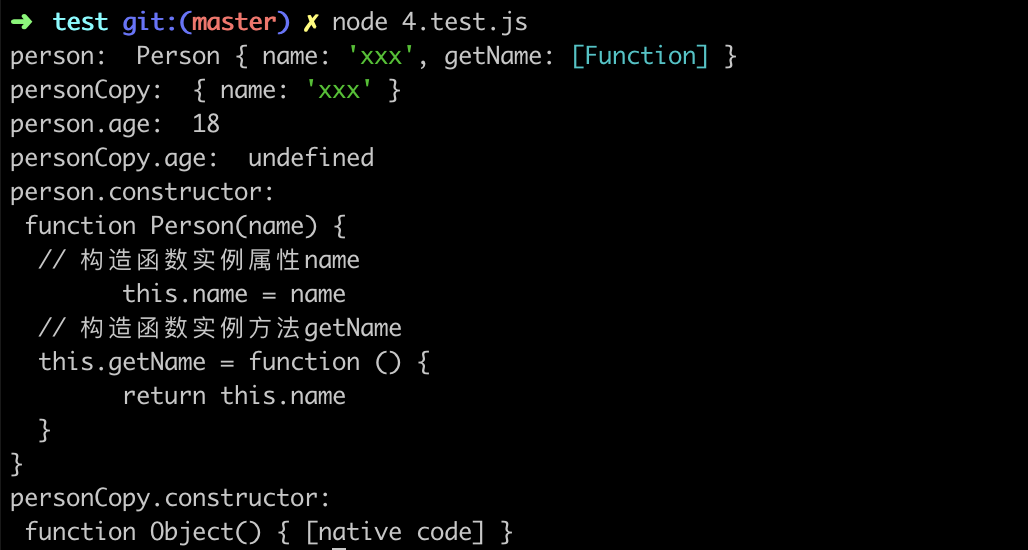
利用 用例 4.test.js (opens new window) 对构造函数进行验证:
function Person(name) {
// 构造函数实例属性name
this.name = name
// 构造函数实例方法getName
this.getName = function () {
return this.name
}
}
// 构造函数原型属性age
Person.prototype.age = 18
const person = new Person('xxx')
const personCopy = JSON.parse(JSON.stringify(person))
在拷贝过程中只会序列化对象可枚举的自身属性,因此无法拷贝 Person 上的原型属性 age ;由于序列化的过程中构造函数会丢失,所以 personCopy 的 constructor 会指向顶层的原生构造函数 Object 而不是自定义构造函数Person
# 2. 手动实现深拷贝方法
# 简单版
我们先来实现一个简单版的深拷贝,思路是,判断data类型,若不是引用类型,直接返回;如果是引用类型,然后判断data是数组还是对象,并对data进行递归遍历,如下:
function cloneDeep(data) {
if(!data || typeof data !== 'object') return data
const retVal = Array.isArray(data) ? [] : {}
for(let key in data) {
retVal[key] = cloneDeep(data[key])
}
return retVal
}
执行 用例 clone1.test.js (opens new window) :
const data = {
str: 'test',
obj: {
foo: 'test'
},
arr: ['test', {foo: 'test'}]
}
const dataCopy = cloneDeep(data)
可以看到对于对象和数组能够实现正确的拷贝

首先是只考虑了对象和数组这两种类型,其他引用类型数据依然与原数据共享同一内存空间,有待完善;其次,对于自定义的构造函数而言,在拷贝的过程中会丢失实例对象的 constructor ,因此其构造函数会变为默认的 Object
# 处理其他数据类型
在上一步我们实现的简单深拷贝,只考虑了对象和数组这两种引用类型数据,接下来将对其他常用数据结构进行相应的处理
# 定义通用方法
我们首先定义一个方法来正确获取数据的类型,这里利用了 Object 原型对象上的 toString 方法,它返回的值为 [object type] ,我们截取其中的type即可。然后定义了数据类型集合的常量,如下:
const getType = (data) => {
return Object.prototype.toString.call(data).slice(8, -1)
}
const TYPE = {
Object: 'Object',
Array: 'Array',
Date: 'Date',
RegExp: 'RegExp',
Set: 'Set',
Map: 'Map',
}
# 主函数实现
接着我们完善对于其他类型的处理,根据不同的 data 类型,对 data 进行不同的初始化操作,然后进行相应的递归遍历,如下:
const cloneDeep = (data) => {
if (!data || typeof data !== 'object') return data
let cloneData = data
const Constructor = data.constructor;
const dataType = getType(data)
// data 初始化
if (dataType === TYPE.Array) {
cloneData = []
} else if (dataType === TYPE.Object) {
// 获取原对象的原型
cloneData = Object.create(Object.getPrototypeOf(data))
} else if (dataType === TYPE.Date) {
cloneData = new Constructor(data.getTime())
} else if (dataType === TYPE.RegExp) {
const reFlags = /\w*$/
// 特殊处理regexp,拷贝过程中lastIndex属性会丢失
cloneData = new Constructor(data.source, reFlags.exec(data))
cloneData.lastIndex = data.lastIndex
} else if (dataType === TYPE.Set || dataType === TYPE.Map) {
cloneData = new Constructor()
}
// 遍历 data
if (dataType === TYPE.Set) {
for (let value of data) {
cloneData.add(cloneDeep(value))
}
} else if (dataType === TYPE.Map) {
for (let [mapKey, mapValue] of data) {
// Map的键、值都可以是引用类型,因此都需要拷贝
cloneData.set(cloneDeep(mapKey), cloneDeep(mapValue))
}
} else {
for (let key in data) {
// 不考虑继承的属性
if (data.hasOwnProperty(key)) {
cloneData[key] = cloneDeep(data[key])
}
}
}
return cloneData
}
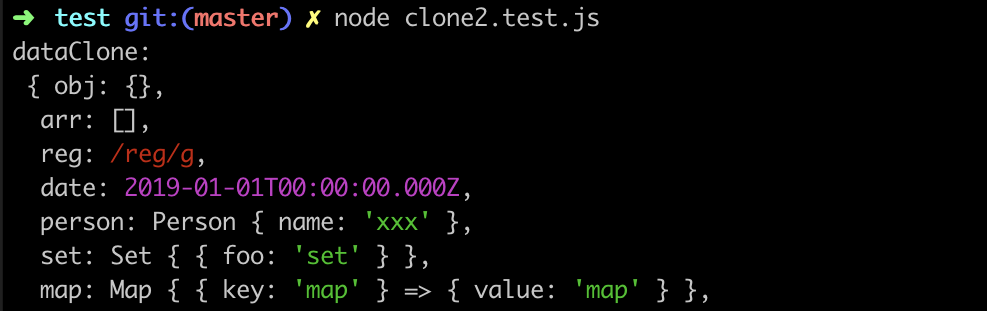
上面的代码完整版可以参考 clone2.js (opens new window) ,接下来使用 用例 clone2.test.js (opens new window) 进行验证:
const data = {
obj: {},
arr: [],
reg: /reg/g,
date: new Date('2019'),
person: new Person('lixx'),
set: new Set([{test: 'set'}]),
map: new Map([[{key: 'map'}, {value: 'map'}]])
}
function Person(name) {
this.name = name
}
const dataClone = cloneDeep(data)
可以看到对于不同类型的引用数据都能够实现正确拷贝,结果如下:
# 关于函数
函数的拷贝我这里没有实现,两个对象中的函数使用同一个内存空间并没有什么问题。实际上,查看了 lodash/cloneDeep 的相关实现后,对于函数它是直接返回的:

到这一步,我们的深拷贝方法已经初具雏形,实际上需要特殊处理的数据类型远不止这些,还有 Error 、 Buffer 、 Element 等,有兴趣的小伙伴可以继续探索实现一下~
# 处理循环引用
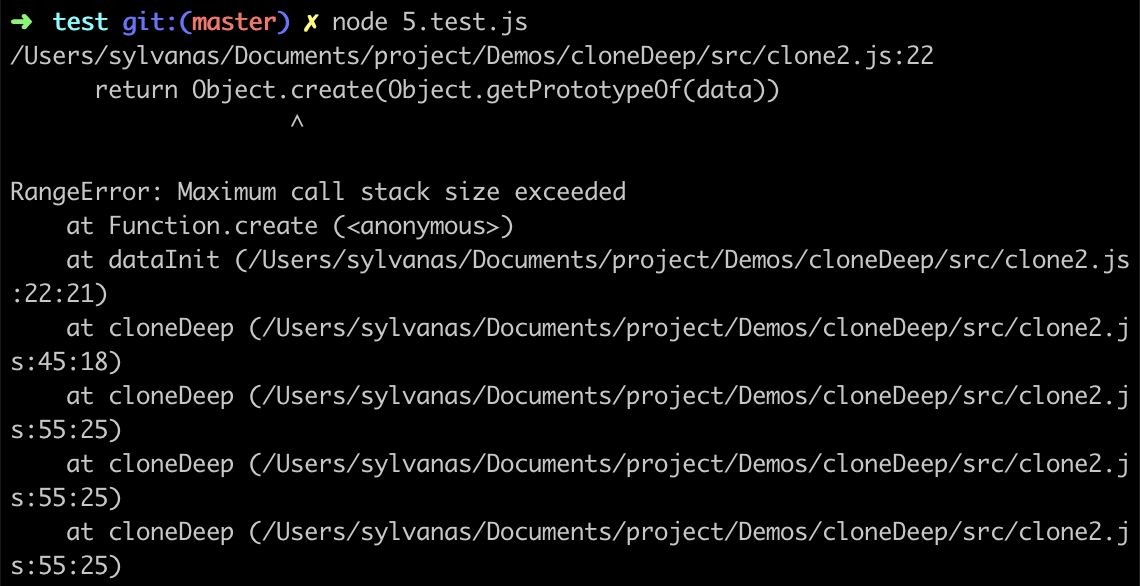
目前为止深拷贝能够处理绝大部分常用的数据结构,但是当数据中出现了循环引用时它就束手无策了
const a = {}
a.a = a
cloneDeep(a)
可以看到,对于循环引用,在进行递归调用的时候会变成死循环而导致栈溢出:
那么如何破解呢?
抛开循环引用不谈,我们先来看看基本的 引用 问题,前文所实现的深拷贝方法以及 JSON 序列化拷贝都会解除原引用类型对于其他数据的引用,来看下面这个例子 (opens new window):
const temp = {}
const data = {
a: temp,
b: temp,
}
const dataJson = JSON.parse(JSON.stringify(data))
const dataClone = cloneDeep(data)
验证一下引用关系:

如果解除这种引用关系是你想要的,那完全ok。如果你想保持数据之间的引用关系,那么该如何去实现呢?
一种做法是可以用一个数据结构将已经拷贝过的内容存储起来,然后在每次拷贝之前进行查询,如果发现已经拷贝过了,直接返回存储的拷贝值即可保持原有的引用关系。
因为能够被正确拷贝的数据均为引用类型,所以我们需要一个 key-value 且 key 可以是引用类型的数据结构,自然想到可以利用 Map/WeakMap 来实现。
这里我们利用一个 WeakMap 的数据结构来保存已经拷贝过的结构, WeakMap 与 Map 最大的不同,就是它的键是弱引用的,它对于值的引用不计入垃圾回收机制,也就是说,当其他引用都解除时,垃圾回收机制会释放该对象的内存;假如使用强引用的 Map ,除非手动解除引用,否则这部分内存不会得到释放,容易造成内存泄漏。
具体的实现 (opens new window)如下:
const cloneDeep = (data, hash = new WeakMap()) => {
if (!data || typeof data !== 'object') return data
// 查询是否已拷贝
if(hash.has(data)) return hash.get(data)
let cloneData = data
const Constructor = data.constructor;
const dataType = getType(data)
// data 初始化
if (dataType === TYPE.Array) {
cloneData = []
} else if (dataType === TYPE.Object) {
// 获取原对象的原型
cloneData = Object.create(Object.getPrototypeOf(data))
} else if (dataType === TYPE.Date) {
cloneData = new Constructor(data.getTime())
} else if (dataType === TYPE.RegExp) {
const reFlags = /\w*$/
// 特殊处理regexp,拷贝过程中lastIndex属性会丢失
cloneData = new Constructor(data.source, reFlags.exec(data))
cloneData.lastIndex = data.lastIndex
} else if (dataType === TYPE.Set || dataType === TYPE.Map) {
cloneData = new Constructor()
}
// 写入 hash
hash.set(data, cloneData)
// 遍历 data
if (dataType === TYPE.Set) {
for (let value of data) {
cloneData.add(cloneDeep(value, hash))
}
} else if (dataType === TYPE.Map) {
for (let [mapKey, mapValue] of data) {
// Map的键、值都可以是引用类型,因此都需要拷贝
cloneData.set(cloneDeep(mapKey, hash), cloneDeep(mapValue, hash))
}
} else {
for (let key in data) {
// 不考虑继承的属性
if (data.hasOwnProperty(key)) {
cloneData[key] = cloneDeep(data[key], hash)
}
}
}
return cloneData
}
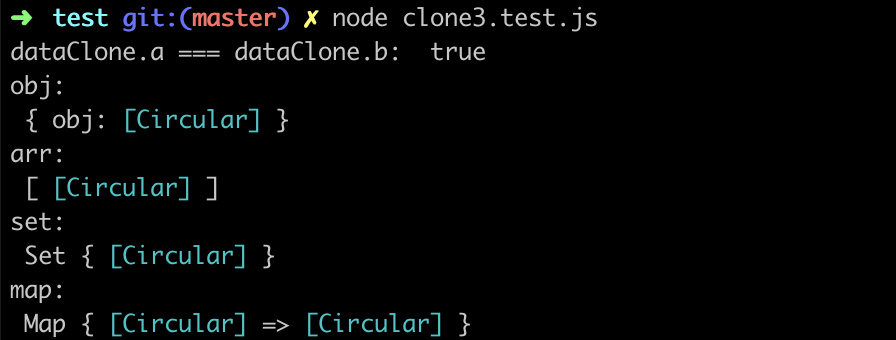
经过改造后的深拷贝函数能够保留原数据的引用关系,也可以正确处理不同引用类型的循环引用,利用下面的用例 clone3.test.js (opens new window) 来进行验证:
const temp = {}
const data = {
a: temp,
b: temp,
}
const dataClone = cloneDeep(data)
const obj = {}
obj.obj = obj
const arr = []
arr[0] = arr
const set = new Set()
set.add(set)
const map = new Map()
map.set(map, map)
结果如下:
# 思考:使用非递归
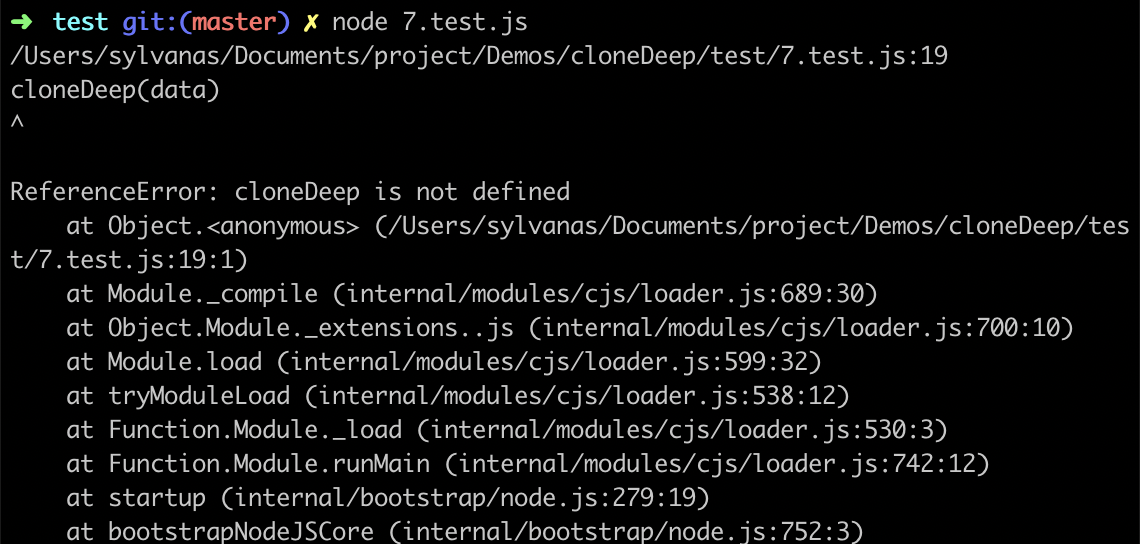
在前面的深拷贝实现方法中,均是通过递归的方式来进行遍历,当递归的层级过深时,也会出现栈溢出的情况,我们使用下面的 create 方法创建深度为10000,广度为100的示例数据:
function create(depth, breadth) {
const data = {}
let temp = data
let i = j = 0
while(i < depth) {
temp = temp['data'] = {}
while(j < breadth) {
temp[j] = j
j++
}
i++
}
return data
}
const data = create(10000, 100)
cloneDeep(data)
结果如下:
那么假如不使用递归,我们应该如何实现呢?
以对象为例,存在下面这样一个数据结构:
const data = {
left: 1,
right: {
left: 1,
right: 2,
}
}
那么换个角度看,其实它就是一个类树形结构:
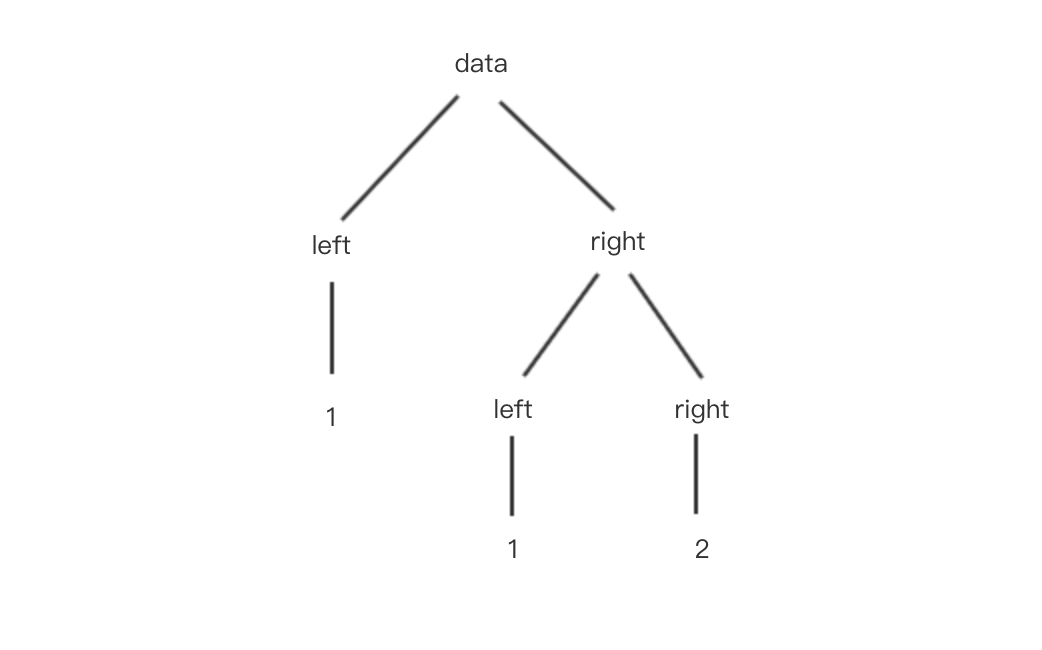
我们对该对象进行遍历实际上相当于模拟对树的遍历。树的遍历主要分为深度优先遍历和广度优先遍历,前者一般借助栈来实现,后者一般借助队列来实现。
这里模拟了树的深度优先遍历,仅考虑对象和非对象,利用栈来实现一个不使用递归的简单深拷贝方法:
function cloneDeep(data) {
const retVal = {}
const stack = [{
target: retVal,
source: data,
}]
// 循环整个stack
while(stack.length > 0) {
// 栈顶节点出栈
const node = stack.pop()
const { target, source } = node
// 遍历当前节点
for(let item in source) {
if (source.hasOwnProperty(item)) {
if (Object.prototype.toString.call(source[item]) === '[object Object]') {
target[item] = {}
// 子节点如果是对象,将该节点入栈
stack.push({
target: target[item],
source: source[item],
})
} else {
// 子节点如果不是对象,直接拷贝
target[item] = source[item]
}
}
}
}
return retVal
}
关于完整的深拷贝非递归实现,可以参考 clone4.js (opens new window) ,对应的测试用例为 用例 clone4.test.js (opens new window) ,这里就不给出了
# 3. 深拷贝方法比较
这里列举了常见的几种深拷贝方法,并进行简单比较
- JSON.parse(JSON.stringify(data))
- jQuery中的$.extend
- 我们这里自己实现的clone3.js (opens new window)中的cloneDeep
- loadsh中的_.cloneDeep
关于耗时比较,采用前文的 create 方法创建了一个广度、深度均为1000的数据,在 node v10.14.2 环境下循环执行以下方法各10000次,这里的耗时取值为运行十次测试用例 (opens new window)的平均值,如下:
| 基本类型 | 数组、对象 | 特殊引用类型 | 循环引用 | 耗时 | |
|---|---|---|---|---|---|
| JSON | 无法处理 NaN 、 Infinity 、 Undefined | 丢失对象原型 | ❌ | ❌ | 7280.6ms |
| $.extend | 无法处理 Undefined | 丢失对象原型、拷贝原型属性 | ❌ (使用同一引用) | ❌ | 5550.6ms |
| cloneDeep | ✔️ | ✔️ | ✔️(待完善) | ✔️ | 5035.3ms |
| _.cloneDeep | ✔️ | ✔️ | ✔️ | ✔️ | 5854.5ms |
在日常的使用过程中,如果你确定你的数据中只有数组、对象等常见类型,你大可以放心使用JSON序列化的方式来进行深拷贝,其它情况下还是推荐引入 loadsh/cloneDeep 来实现
# 小结
深拷贝的水很“深”,浅拷贝也不“浅”,小小的深拷贝里面蕴含的知识点十分丰富:
- 考虑问题是否全面、严谨
- 基础知识、api熟练程度
- 对深拷贝、浅拷贝的认识
- 对数据类型的理解
- 递归/非递归(循环)
- Set、Map/WeakMap等
我相信,要是面试官愿意挖掘的话,能考查的知识点远不止这么多,这个时候就要考验你自己的基本功以及知识面的深广度了,而这些都离不开平时的积累。千里之行,积于跬步,万里之船,成于罗盘
本文如有错误,还请各位批评指正~